
Marketing Analytics #7: Recap & Appendix
Actually Done This Time

Links to Other Parts
Conclusion
Congratulations on getting through the weeds of an example marketing data analysis!

If you’re reading this, then you’ve seen the 5-step analysis process in action:
In Step 1, you saw how to form a good research question
In Step 2, you followed along to see how a data scientist would take a first look through a descriptive statistics readout for a dataset
In Step 3, you identified strange-looking data series and saw how to analyze them for outliers and measurement artifacts
In Step 4, you saw an example analysis test if two variables meaningfully relate in our banking dataset
Finally in Step 5, you saw some ways to test for and avoid common statistical pitfalls after finding an analysis answer
The first time you go form and answer your own research question may feel scary, but you now have a flashlight to guide you in the dark.1
If your company has recently implemented or is considering a new self-service tool, don’t be afraid of getting your hands dirty in data analysis, even if you don’t have a data science background.
With the steps above, any marketer can take advantage of the new power at their disposal to better serve their customers and rise above competitors.
If you’re interested in additional help getting up to speed on a newly-installed tool, how to drive outcomes with data-driven analysis, or want to have an answer to your specific questions, reach out to me via email or comment!
Code and Relevant Links

Throughout this tutorial, we worked through a data extract from a Portuguese bank’s call center from 2008 to 2013. The initial analysis worked to determine which factors surrounding a direct marketing call were most responsible for closing a sale of long-term deposits.
The factors that were identified as most important in the paper were removed in the dataset, so we will be looking through potential other factors to test to increase sales.
To be as cross-platform as possible, relevant calculations and code will be available for reference in the above Jupyter Notebook (unfortunately, I cannot upload an ipynb to this platform, so email me if you want a copy).
Assumptions:
There is no seasonality in the data
Our only success factor is number of deposits completed, not the amount within each deposit
Useful Links:
Use the bank-additional-full.csv file
Appendix:
Hypothesis Question Examples:
A few questions that could lead to a testable hypothesis in our dataset could be:
Does a positive change in the 3-month Euribor rate positively correlate to a higher likelihood of making a long-term deposit?
Does having previously been in a campaign make someone more likely to make a deposit?
Are there any ages that are most likely to make a deposit when contacted?
Does the contact method (fixed-line telephone or cell) affect deposit rate?
Some questions are important to answer for the sake of your business but cannot be resolved by data analysis. A few examples:
Are we spending our budget well?
Spending it well relative to what? Until there are specific goals or metrics to measure against, data analysis can’t answer this question
How can we be more innovative?
Innovation usually involves approaching a customer need from a new perspective. Analyzing and optimizing the current ways that you do business is unlikely to lead to a radical new perspective. I’ve written more on the subject previously here.
How can we improve the bottom line?
This question is too broad to answer with data analysis. In order to approach this, break the question into more digestible parts repeatedly until an answerable question emerges. An example ordering is below
How can we improve profit?
How can we reduce costs?
How can we reduce our inventory holding costs?
How can we better predict our seasonal demand to reduce product holding time?
What times in the year does our inventory ordering regularly overshoot the demand?
Are we people first?
If you’re asking yourself this, the answer is no
Data analysis can’t answer this question anyway
Descriptive Statistics Examples:
These often include, but are not limited to, the following measurements on an example set of (1, 2, 1, 7, 55, 1, 1, 4, 5, 7, 4, 7, 8, 9, 10):
Range, minimum, and maximum
What the extremes and dimensions your dataset covers
For our example, the minimum would be 1, the maximum would be 55, and the range would be 55-1 or 54
Mean
Also known as the ‘arithmetic mean’ or just ‘average’, this value reflects the ‘center of mass’ of the data set
For our example, the mean, ~8.43, is the sum of all values, 118, divided by the count of all values, 14
Median
Sample in the middle of an ordered population. This value reflects the center of measurement for the data set. Often this can be useful when there are many measurement values far away from the mean
For our example, the set—when ordered—is
(1, 1, 1, 1, 2, 4, 4, 5, 7, 7, 7, 8, 9, 10, 55), so the median is 5
Mode
Most commonly appearing value in a set
For our example, there are 4 instances of the value ‘1’,
(1, 1, 1, 1, 2, 4, 4, 5, 7, 7, 7, 8, 9, 10, 55), so 1 is the mode
Variance
Variance measures the distance between values and the mean. If there is a larger variance, then you’ll need more sample measurements to prove statistical significance
To perform this calculation, further reading is available here
For our example, the variance is 177.84, indicating a large dispersion from the mean values
Skew
Skewedness describes the shape of a distribution and if it leans more left or right of a sample bell curve. A highly skewed distribution may require different analysis methods than a non-skewed distribution.
To perform this calculation, further reading is available here
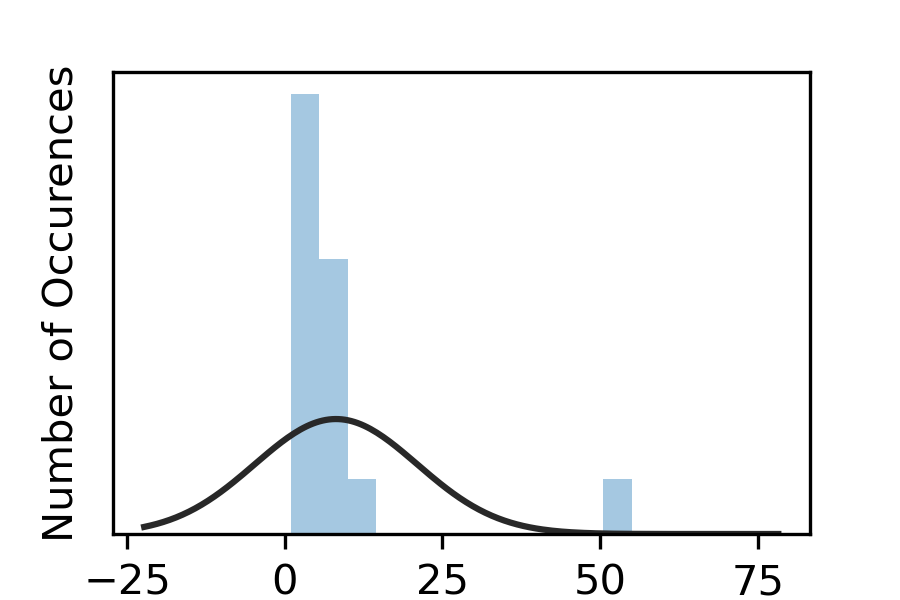
For our example, the skewedness is 3.51—above 1—indicating a right-skewed distribution due to the outlier of 55
High-Level Step 4 Approach for a New Dataset
Use the knowledge of the data gathered in Steps 1-3 to choose an appropriate statistical method, do the initial analysis on part of your data set to determine effect size and significance relevant to your research question, and see if the trends observed carry forward for the portion of the dataset withheld from the analysis.
This step can take many forms depending on your dataset and goals, but if the previous steps have been completed, this analysis should be well-defined and straightforward.